
Aug 29, 2024
By
ModelBox Team

Today Qwen announced the grand release of Qwen2-VL, the latest iteration in the Qwen model family. Qwen2-VL builds on its predecessor, Qwen-VL, enhancing its vision-language capabilities to set new standards in the field. After Qwen2 Math, Qwen2 Audio, here's another bomb of AI.
Advancements in Visual Understanding
Qwen2-VL represents a significant leap forward in visual comprehension. It excels in handling images of varying resolutions and aspect ratios, delivering state-of-the-art performance on key benchmarks like MathVista, DocVQA, RealWorldQA, and MTVQA. This improvement empowers users with a tool that can process visual data with unprecedented accuracy, whether in complex educational content or real-world scenarios.
Video Comprehension at New Lengths
One of the standout features of Qwen2-VL is its ability to understand videos longer than 20 minutes. This capability is invaluable for applications in video-based question answering, dialogue generation, and content creation, offering users a deeper and more nuanced understanding of long-form video content.
A Versatile Visual Agent
Qwen2-VL’s integration as an agent in mobile devices, robots, and other hardware is a game-changer. With enhanced reasoning and decision-making skills, it can operate autonomously within a visual environment, executing tasks based on text instructions and visual cues. This makes it an indispensable tool for automated operations in a variety of settings, from personal devices to industrial robots.
Multilingual Mastery
To serve a global audience, Qwen2-VL now supports text recognition in a wide range of languages beyond English and Chinese. It can accurately interpret text within images in European languages, Japanese, Korean, Arabic, Vietnamese, and more, making it an accessible tool for users worldwide.
Open Source and Accessible
Qwen are releasing Qwen2-VL-2B and Qwen2-VL-7B under the Apache 2.0 license. The models are integrated into Hugging Face Transformers, vLLM, and other third-party frameworks, ensuring broad accessibility. Additionally, the API for Qwen2-VL-72B is now available, offering unparalleled performance for those who require cutting-edge visual language processing capabilities.
Performance
Our extensive evaluation of Qwen2-VL reveals its exceptional performance across six key dimensions: complex problem-solving, mathematical abilities, document and table comprehension, multilingual text-image understanding, general question-answering, and video comprehension. The 72B model, in particular, consistently outperforms even the most advanced closed-source models, demonstrating its superiority in document understanding and beyond.
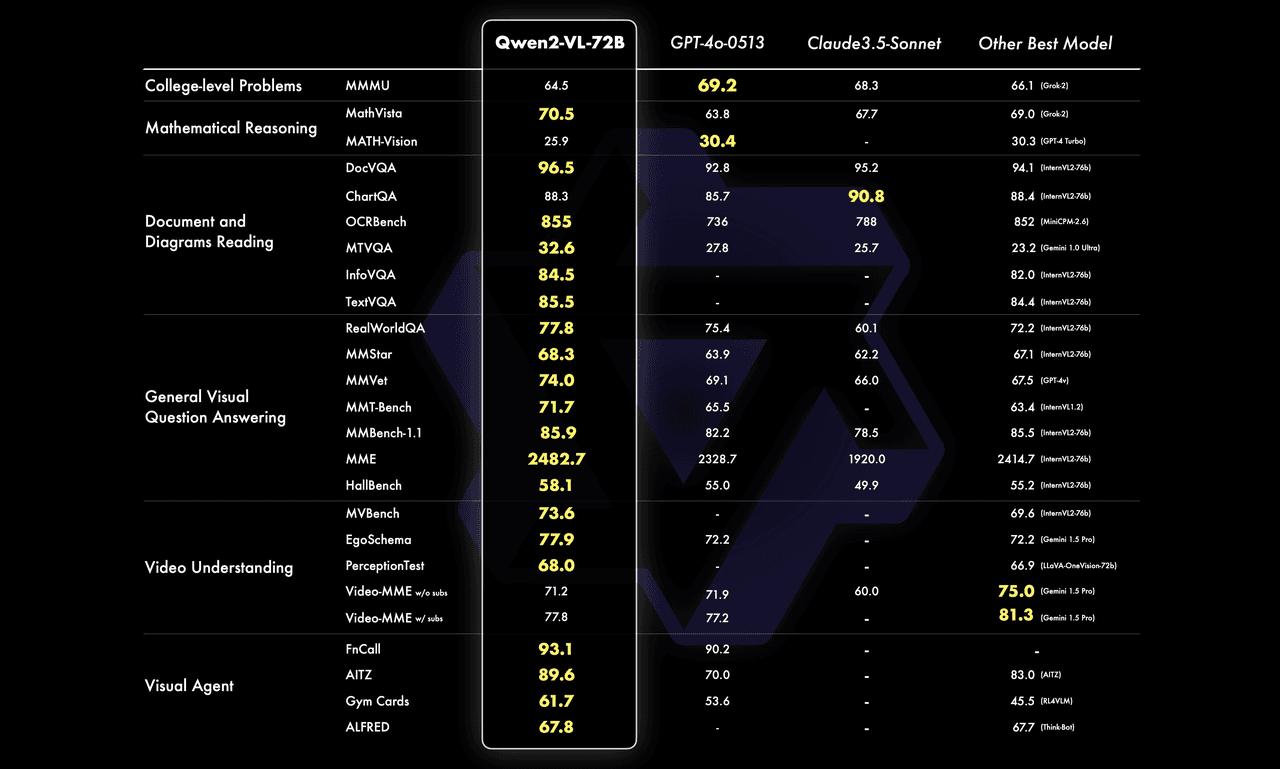
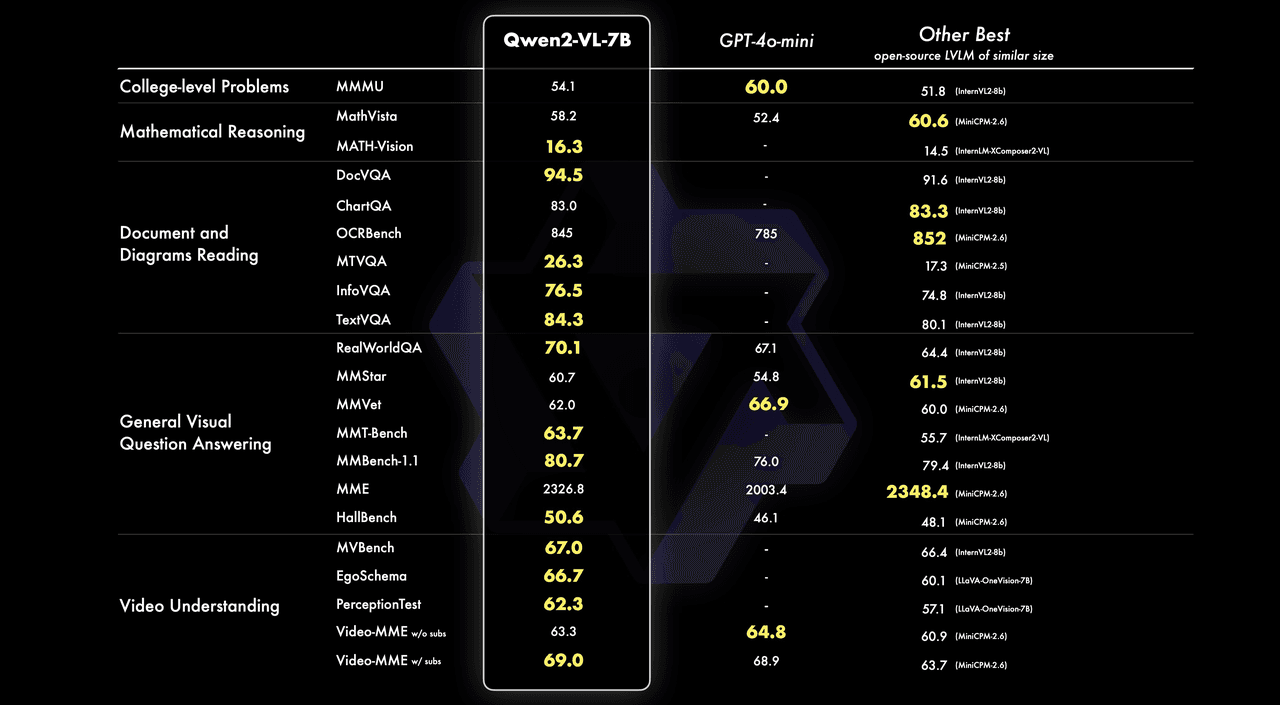
At the 7B scale, Qwen2-VL maintains robust support for image, multi-image, and video inputs, offering a cost-effective solution without compromising on performance. Meanwhile, our compact 2B model, optimized for mobile deployment, excels in video-related tasks and general scenario question-answering, outperforming other models of similar size.
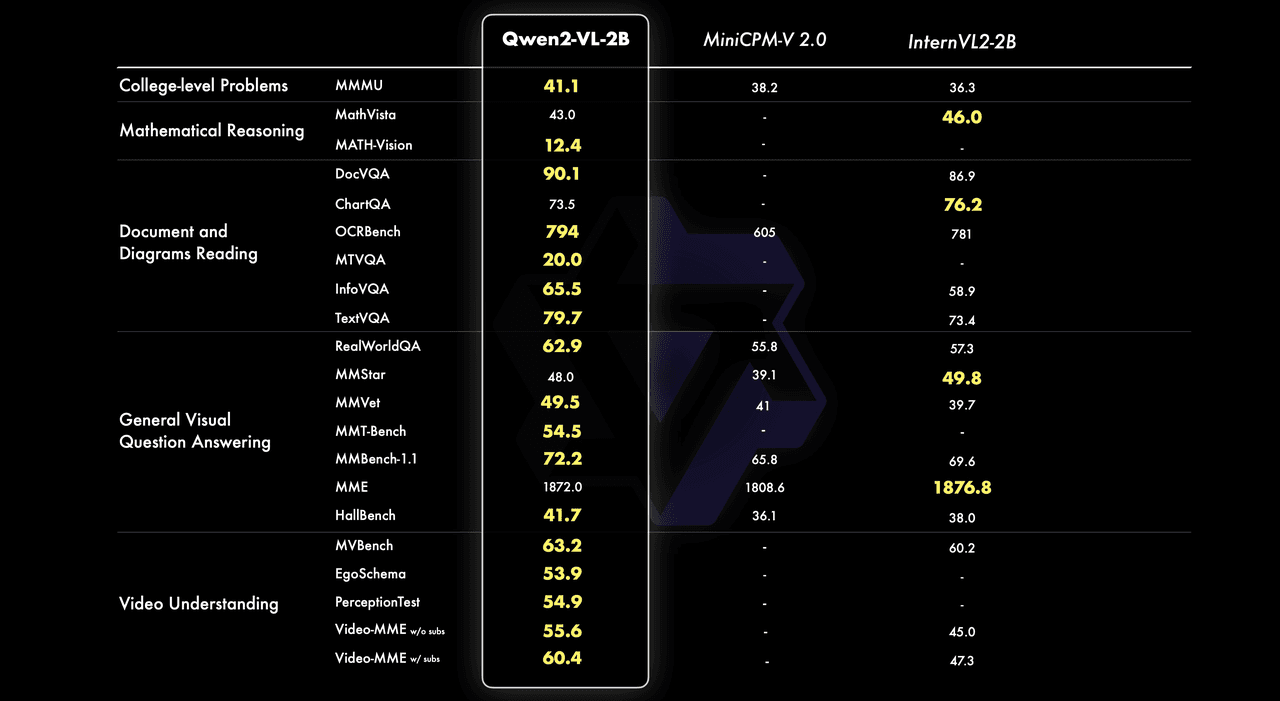
Enhanced Recognition and Reasoning
Qwen2-VL’s enhanced recognition capabilities extend beyond traditional object recognition to understand complex relationships between multiple objects in a scene. The model also excels in recognizing handwritten text and multiple languages within images, making it a versatile tool for users worldwide. Its advanced reasoning capabilities allow it to solve real-world problems by analyzing images, interpreting charts, and executing complex instructions, bridging the gap between visual perception and logical reasoning.
Real-Time Video and Live Chat Capabilities
Qwen2-VL’s prowess extends to real-time video analysis, enabling it to summarize video content, answer related questions, and maintain a continuous dialogue with users. This makes it an ideal assistant for tasks that require ongoing interaction with video content.
Architectural Innovations
Building on the Qwen-VL architecture, Qwen2-VL incorporates a Vision Transformer (ViT) model and Qwen2 language models. With Naive Dynamic Resolution support and Multimodal Rotary Position Embedding (M-ROPE), the model can handle arbitrary image resolutions and seamlessly integrate textual, visual, and video positional information, mimicking human visual perception more closely.
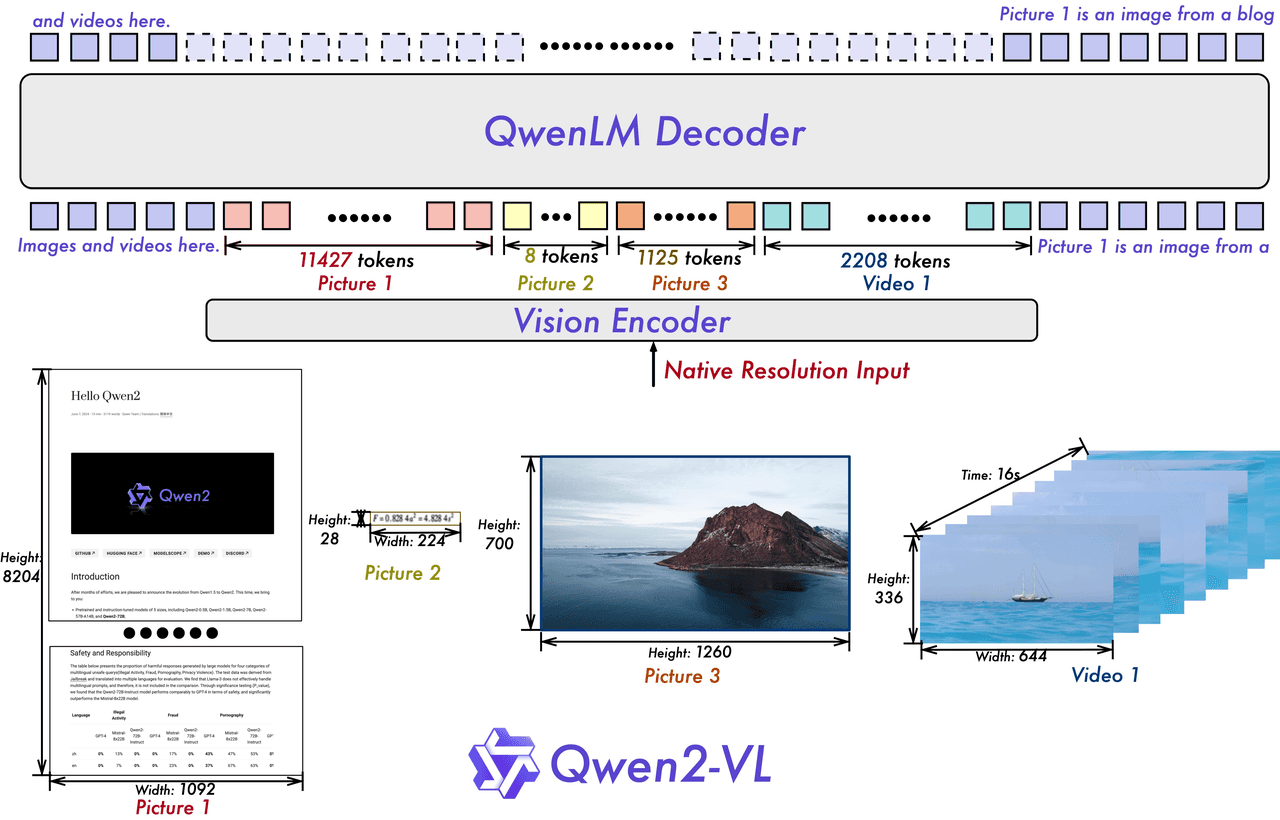
Naive Dynamic Resolution support.

Multimodal Rotary Position Embedding (M-ROPE)
Get Started with Qwen2-VL
The Qwen2-VL-72B model is available through our API, while the 2B and 7B models are open-sourced on Hugging Face and ModelScope. We encourage developers to explore these models, taking advantage of their advanced capabilities and the comprehensive toolkit we provide for handling various visual inputs.
In summary, Qwen2-VL represents a significant advancement in vision-language models, offering enhanced capabilities in visual understanding, video comprehension, and multilingual support. We are excited to see how the community will leverage these tools to create innovative solutions and applications. Enjoy exploring Qwen2-VL and unlocking new possibilities in AI-driven visual language processing! https://qwenlm.github.io/blog/qwen2-vl/
Learn more about ModelBox
Official Website: https://www.model.box/
Models: https://app.model.box/models
Medium: https://medium.com/@modelbox
Discord: discord.gg/HCKfwFyF